The CAP Theorem after two decades: where are we in 2024?
5 min readKey points
Databases are critical in managing information for applications, ensuring data is correctly stored, updated, and retrieved.
In a single-node database, network partitions are not major concern. However, as systems grow in complexity and scale, while having data replicated across multiple nodes for redundancy and performance, challenges in maintaining data consistency, availability, and partition tolerance arise. This is where the CAP theorem becomes relevant, a fundamental principle that guides the design and operation of distributed systems.
In this article, we are going to look closer at the CAP theorem as of 2024.
The CAP theorem
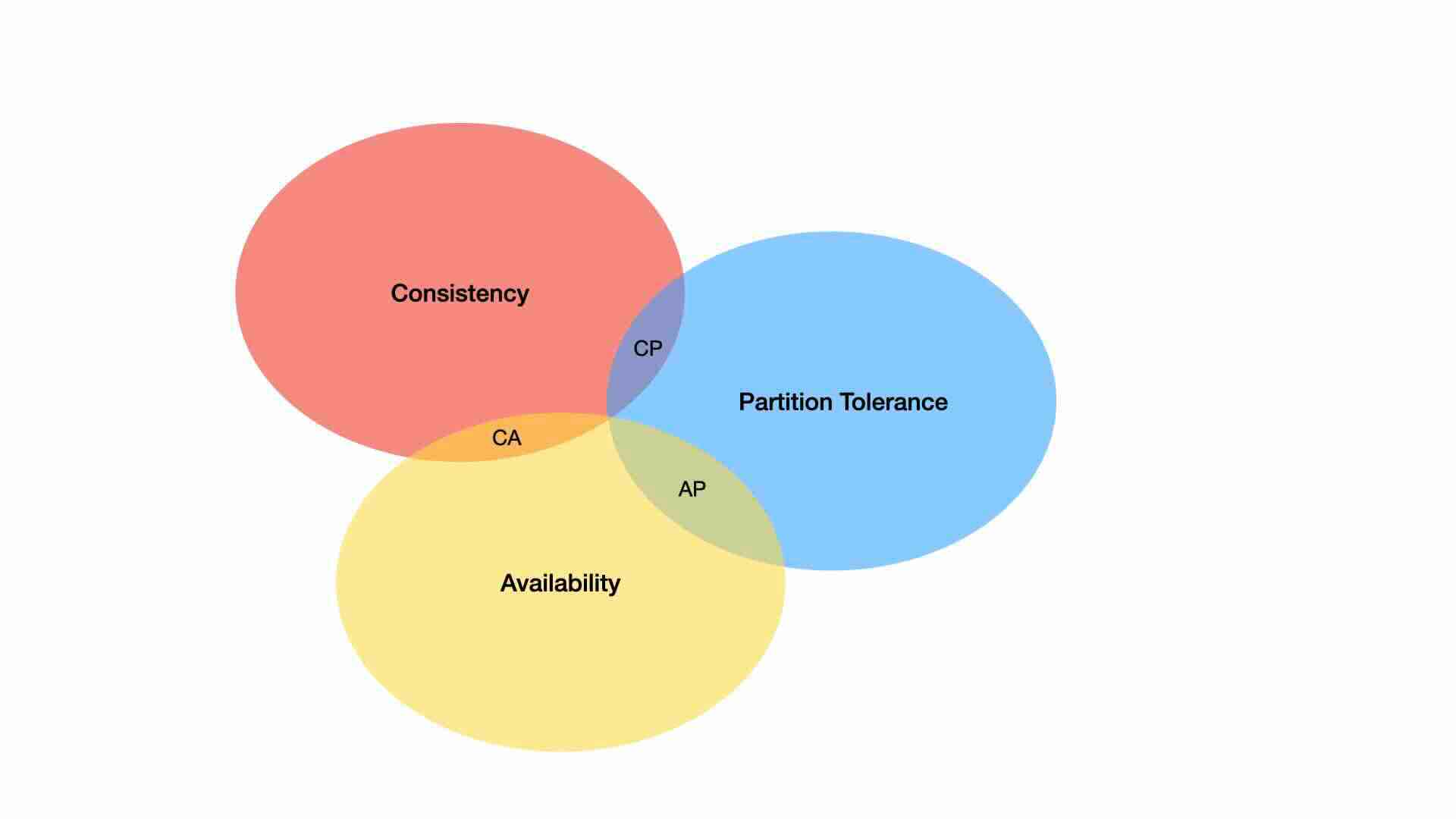
CAP stands for Consistency, Availability and Partition tolerance.
According to Wikipedia, Consistency means every read receives the most recent write or an error. Availability means every request receives a non-error response, without the guarantee that it contains the most recent write. Partition tolerance means the system continues to operate despite an arbitrary number of messages being dropped, or delayed by the network between nodes.
The CAP theorem highlights a trade-off in system design: prioritizing two properties often means compromising on the third. For instance, a system optimized for consistency and availability might struggle with network partitions, leading to potential data inconsistencies. Conversely, focusing on consistency and partition tolerance could result in decreased availability, making the system temporarily inaccessible to some users during network issues.
Essentially design-wise must decide:
- cancel the operation and thus decrease the availability but ensure consistency
- proceed with the operation and thus provide availability but risk inconsistency.
Do you Know?
The CAP theorem, which also called Brewer's theorem, is named after the computer scientist Eric Brewer.
According to Wikipedia, the theorem was published as the CAP principle in 1999 and presented as a conjecture by Brewer at the 2000 Symposium on Principles of Distributed Computing (PODC). In 2002, Seth Gilbert and Nancy Lynch of MIT published a formal proof of Brewer's conjecture, rendering it a theorem.
Database Flavors
The CAP theorem has been serving as a guiding principle in the design and selection of database systems, influencing how technologies prioritize between consistency, availability, and partition tolerance. To illustrate the CAP theorem's implications in practical terms, let's examine how mainstream database options and public cloud database options coping with it.
Relational Databases
As of 2024, mainstream relational databases including Oracle DB, SQL Server, MySQL, PostgreSQL etc. Traditionally optimized for consistency and availability (CA), the relational databases ensure transactions are processed reliably, making them ideal for applications requiring strict data integrity, such as financial systems. However, they may struggle with partition tolerance, meaning their performance can degrade in distributed environments where network partitions occur.
NoSQL Databases
Popular options include Cassandra, MongoDB etc. they are designed with partition tolerance and availability (AP) in mind, and offering flexibility and scalability for distributed systems, as well as in handling large volumes of data across many servers. Cassandra, for instance, allows for eventual consistency to achieve high availability and partition tolerance, making it suitable for applications where immediate consistency is not critical. However, this comes at the cost of strong consistency, potentially leading to temporary data discrepancies.
NewSQL Databases
It is a class of relational database management systems that seek to provide the scalability of NoSQL systems for online transaction processing workloads while maintaining the ACID guarantees of a traditional database system. Google Spanner, CockroachDB and TiDB are all belonging to the NewSQL databases paradigms. Google Spanner, for example, uses a globally distributed clock architecture named "TrueTime" to maintain strong consistency across distributed systems. It supports ACID transaction consistency, thereby providing better data integrity than most of its NoSQL alternatives.
Some might contend that the CAP Theorem no longer applies, given that NewSQL systems like Google Spanner appear to simultaneously uphold all CAP principles. However, this isn't the case. The real genius behind Google's engineering efforts lies in their capacity to minimize the risk of network Partition Tolerance 'P' problems, thanks to their exceptionally fast, globally redundant private network that connects multiple data centers.
Public Cloud Offerings
Over the recent decade, with the surge in public cloud services, there has been a growing interest in solutions from major providers like Amazon, Microsoft, and Google, including services such as Aurora, DynamoDB and CosmosDB. These managed SQL and NoSQL database services are typically architected to prioritize Availability and Partition Tolerance (AP), offering scalable and highly available solutions. For instance, they may employ eventual consistency to enhance availability and partition tolerance across numerous data centers.
Nonetheless, such offering usually also introduces options for users who need stronger consistency for particular use cases. By employing strongly consistent reads, it ensures that a read operation retrieves the most recent data. This capability, however, may lead to slight higher latency and decreased availability in some situations, highlighting the necessary compromises dictated by the CAP theorem.
Key Takeaways
- The CAP theorem is not outdated, but our understanding of how to work within its constraints has evolved.
- Choosing 'two out of three' in the CAP theorem is still necessary but modern databases and systems give engineers more flexibility.
- Distributed systems are complex, and the CAP theorem remains a valuable tool for reasoning about their behavior and making informed design decisions.
Summary
In conclusion, the CAP theorem is a fundamental principle that underpins the functionality of distributed databases, providing a framework for understanding the trade-offs between consistency, availability, and partition tolerance. By carefully considering these factors, developers can build systems that best serve their application's needs, ensuring reliable data management in an increasingly connected world.