What’s Really Happening Behind a Database Transaction
5 min readKey points
When managing a database, we often deal with transactions— like moving money between bank accounts. These transactions are crucial because they help keep our data accurate and consistent. But when many transactions happen at once, things can get messy without the right controls. This is where transaction isolation levels come in. They help manage how transactions interact, while making sure our data stays reliable.
What's a Database Transaction?
Think of a transaction as a package of several operations. It’s all or nothing—if one part fails, the whole transaction is rolled back, as if it never happened. This keeps errors from messing up your data.
If you are programming in Java, and with Spring framework as your JPA. the @Transactional annotation is no stranger. However, have you thought through what has been really happening behind the scene?
Let’s start this by looking at an example utilizing the Spring Data JPA, where we may use the @Transactional annotation to define the scope and configuration of a transaction, including the isolation level.
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import javax.persistence.EntityManager;
@Service
public class AccountService {
@Autowired
private EntityManager entityManager;
@Transactional(isolation = Isolation.READ_COMMITTED)
public void transferFunds(Long fromAccountId, Long toAccountId, BigDecimal amount) {
Account fromAccount = entityManager.find(Account.class, fromAccountId);
Account toAccount = entityManager.find(Account.class, toAccountId);
fromAccount.setBalance(fromAccount.getBalance().subtract(amount));
toAccount.setBalance(toAccount.getBalance().add(amount));
entityManager.merge(fromAccount);
entityManager.merge(toAccount);
// Other operations..
}
}In this example, the transaction management is declarative. The @Transactional annotation specifies that the transferFunds method should run within a transaction context with the READ_COMMITTED isolation level. Behind the scene, Spring Data JPA handles the transaction's start, commit, and rollback operations based on the method's execution result.
What is Isolation and Why it Matters
Now let’s take a step-back, and look at the specification of the setup here.
What is “isolation”?
Without isolation, transactions could interfere with each other, leading to problems like:
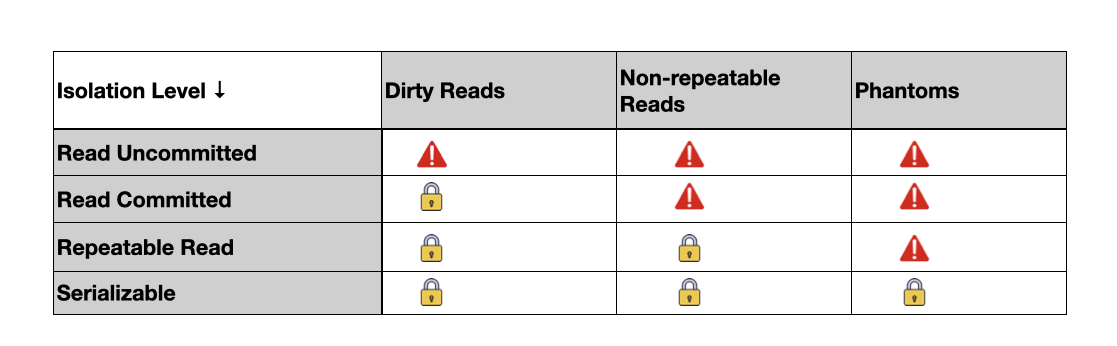
- Dirty Reads: One transaction reads changes from another that hasn’t finished yet. If the second transaction gets canceled, the first one has read data that doesn’t really exist.
- Non-Repeatable Reads: You read a record, and while you're still working, another transaction changes or deletes that record. When you look again, the data has changed or gone.
- Phantom Reads: You read a set of records matching some criteria. Then another transaction adds or removes records that fit those criteria. If you check again, you find different results.
Let's consider an online banking system where a user wants to transfer $100 from their savings account to their checking account. This seemingly simple operation involves several steps:
- Check the savings account balance to ensure it has at least $100.
- Withdraw $100 from the savings account.
- Deposit $100 into the checking account.
- Record the transaction in the transaction history.
All these operations combined form a single transaction. If any of these steps fail, the entire transaction should be rolled back to prevent inconsistencies in the account balances.
Now, let's see how different isolation levels handle this scenario, focusing on the potential issues they aim to solve. We'll include pseudocode and SQL/Java examples to illustrate each level.
Read Uncommitted
Scenario: While Transaction A is transferring money between accounts, Transaction B can see the intermediate changes before A is completed.
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;
BEGIN TRANSACTION;
-- Assume account balances are checked and updated here
COMMIT;The issue with this level of isolation, is that Transaction B might see the savings account debited before the checking account is credited, potentially leading to decisions based on uncommitted data (like issuing a loan based on the current, inaccurate account balance).
Read Committed
Scenario: Transaction B can only see changes made by Transaction A after A is fully completed and committed.
SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
BEGIN TRANSACTION;
SELECT balance FROM accounts WHERE account_id = 1;
-- Other operations
COMMIT;This prevents dirty reads from case 1. However, if Transaction B reads the balance again, it might get a different result due to other completed transactions.
Repeatable Read
Scenario: Once Transaction A reads the balance of an account, that balance cannot change during the transaction. Other transactions can't modify the account balance until A completes.
SET TRANSACTION ISOLATION LEVEL REPEATABLE READ;
BEGIN TRANSACTION;
SELECT balance FROM accounts WHERE account_id = 1;
-- This balance remains constant for the duration of the transaction
COMMIT;This level isolation eliminates non-repeatable reads. Transaction A sees consistent data throughout.
Serializable
Scenario: Transactions are fully isolated, as if running sequentially. If Transaction A is transferring money, Transaction B must wait until A is done before starting.
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
BEGIN TRANSACTION;
SELECT balance FROM accounts WHERE account_id = 1 FOR UPDATE;
-- Ensures complete isolation by locking the account for the transaction duration
COMMIT;This level of isolation essentially prevents all forms of read anomalies, including phantom reads. The downside of this approach is all transactions are considered serializable, that reducing the throughput of the database application.
Now let's put the isolation levels side-by-side with the transactional risks.
Summary
We've looked at how different transaction isolation levels affect databases, from the simplest level that allows reading unfinished transactions, to the most secure level that ensures data is completely accurate. Each level balances data correctness with how fast the database works.
Understanding these levels is crucial for designing databases, especially in areas like banking, healthcare, and online shopping, where correct data is critical. Real learning comes from trying these levels out with your own database projects. See how they change the way your database handles lots of transactions at once, and how often it locks up. This will help you find the best setup for your needs.